每天开始工作的第一件事情是查看客人都会搜索哪些车站直接的路线,以及客人们都查看了哪些车站的信息。从中我会过滤出哪些车站还没有维护过,接下来我会利用工作间隙或者切换思路的时候去装修一下这些车站。装修车站是指搜索一些该车站相关的介绍、建筑物照片、大堂候车室照片、轨道站台图片、站内地图等等。比如今天早晨我装修了德国的Köthen和Friedrichshafen Fähre、日本的新岩国駅、俄罗斯的Владивосток(Vladivostok、符拉迪沃斯托克又称海参崴)、意大利的Avigliano Citta’和Avigliano、斯洛伐克的Bratislava Hlavná Stanica。
在寻找车站信息的常见挑战是,绝大多数车站用中文根本搜索不到有用的信息。甚至对于很多小车站来说,用英文都不会有有价值的结果。所以我的习惯是用本国语言去搜索,比如Köthen,我搜索的是”Köthen Bahnhof”,韩国的龟尾,我需要用“구미기차역”。搜索布拉迪斯拉发中央火车站(Bratislava Hlavná Stanica),不光需要用斯洛伐克语,而且有时候用当地常用的缩写会找到更多的信息,比如用“Bratislava hl.st.”
找不到(Unfindable)
尽管互联网上有很多信息,但是受语言、专业等限制,因为找不到合适的关键字,我们根本没有机会找到所需要的信息。
碎片化(Fragmentation)
对于一个车站来说,海外客人需要的信息可能包括各种照片、地图、列车时刻表、站台换乘信息、车站停车场、存包、服务电话、地址、货币兑换、核酸检测、语言翻译等等林林总总的信息,但是很少有机会去找到同一个网页把相关的信息聚合在一起。
利基聚合(Niche Aggregation)
解决Unfindable和Irrelevant问题的方案是建立车站的利基聚合(Niche Aggregation)。
信息聚合
从海外旅客的角度把各种信息集成到同一个网页,愈来越多的客人会花几十分钟甚至一两个小时在G2Rail网站上研究车站、路线、车票、价格。
建立关联(Relevance)
跨语种关联
在同一个车站的不同关键字直接建立关联,比如Köthen对应于克滕(中文)、ケーテン(日文)、쾨텐(韩文)、Koethen(英文)。

逻辑关联
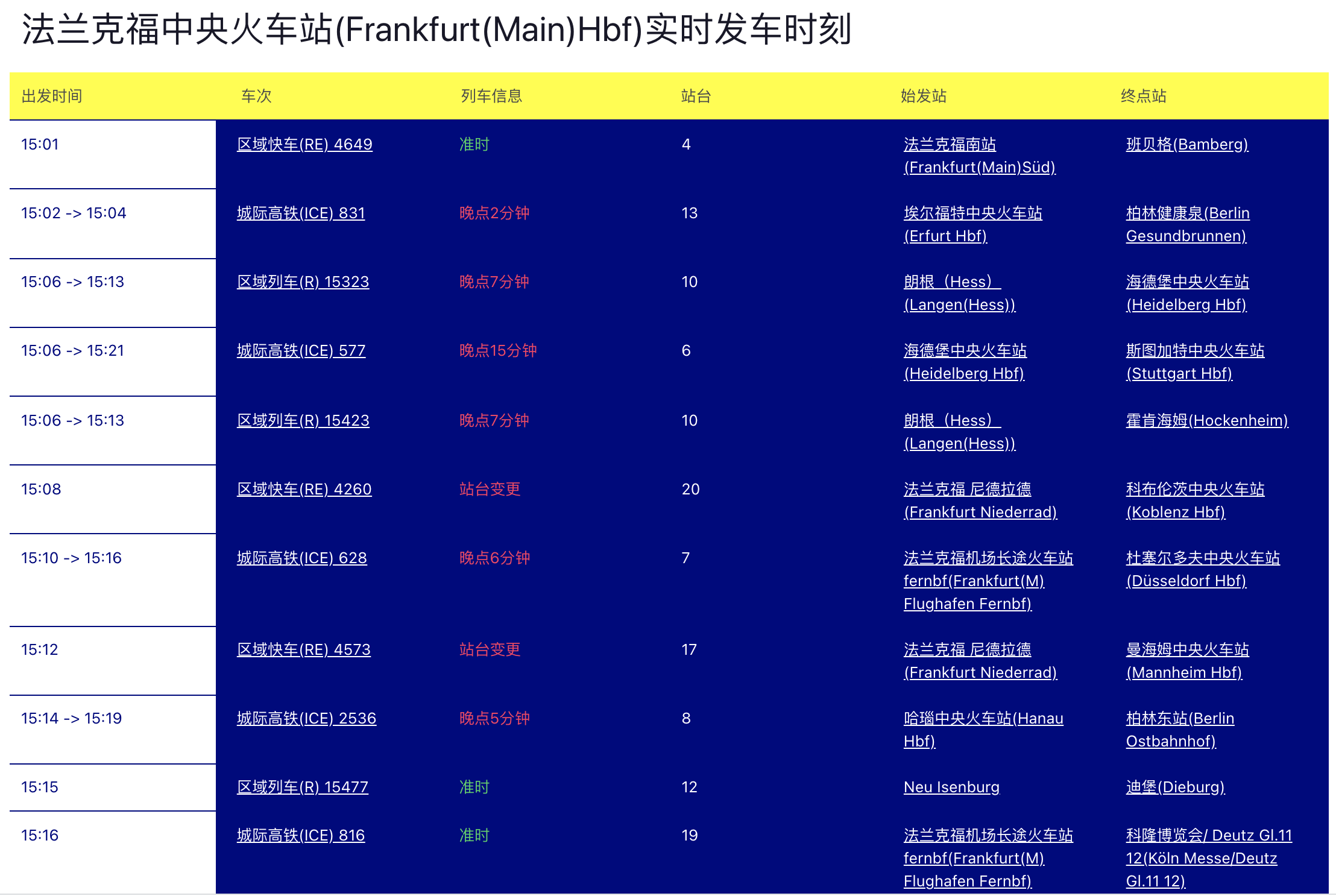
通过法兰克福中央火车站(Frankfurt Hbf)的实时出发/到达列车时刻表,可以很方便的在不同车站直接建立关联。
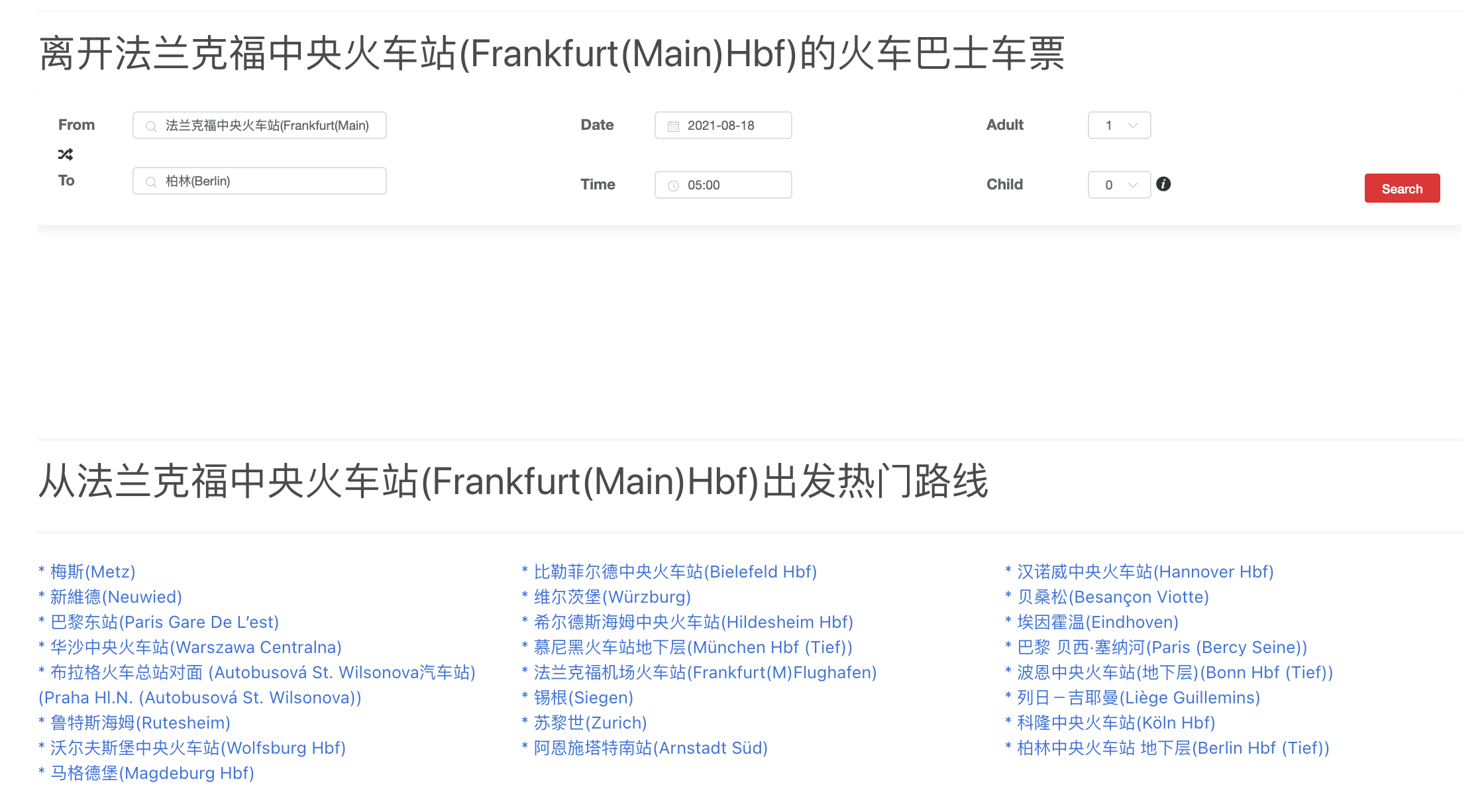
通过G2Rail出行大数据中从法兰克福中央火车站出行的最热门路线也可以建立更多法兰克福与重要车站直接建立链接。
训练搜索引擎
通过建立车站利集聚合页面,也可以训练各大搜索引擎在相关关键字直接建立关联,从而在搜索引擎各种关键字竞争中占据一席之地。
