在Sprint结束后经常会出现故事没有完成的情况。原因有很多,有可能是测试没有完成,也有可能是发现了原来没有估计到的需求,也可能是需要大的重构。一般情况下,这种故事都会变成下一个迭代的高优先级的故事,Scrum团队都会在接下来的迭代中首先完成这个故事。但是怎样去估计和计划这类没有完成的故事,大家没有形成共识。
通常情况下有两种处理方法:
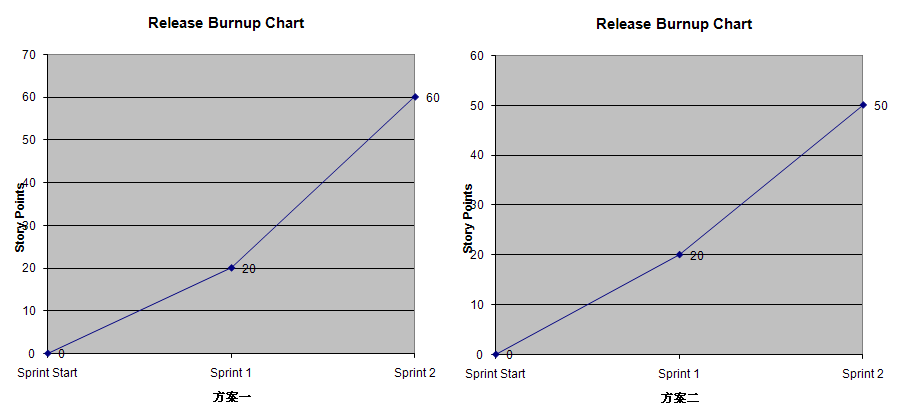
- 故事的故事点估计值不变,下个迭代完成后自动计算入下个迭代的速率(Velocity)。参见图1 方案一。方案一的累计完成故事点比较高,因为有一部分故事点其实是上一个Sprint完成的。
- 对这个故事剩下的任务重新估计,下个迭代完成后,只把新的估计值(故事点)计算入下一个迭代的速率。参见图2 方案二。方案二的累计完成故事点只有50,因为有一部分在第一个Sprint完成的任务,由于在第二个Sprint计划时,做了重新估计,已完成的那部分没有被计算在内。
很多团队都会采用第一种方法。理由很简单:
- 从项目管理的角度如果不把这部分投入(Effort)计算在内,就相当于一部分投入没有被追踪,丢失了,这对项目组和管理层都是不可接受的。把所有的故事点自动计入下一个Sprint,就可以Justify项目组的全部工作。从图1来看,项目组得到了更多的点数,两个迭代60点。
- 项目组的在下一个Sprint会得到一个比较高的速率值,大家都会很高兴,管理层也会很高兴,因为生产率提高了,从第一个迭代的20上升到第二个迭代的40。尽管从长远来看这个生产率是不长远的。
我更倾向于第二种方法,为什么?
- 不”掺水”的历史数据,更可靠的预测依据
项目组应该在磨合中发现自身在一个Sprint中到底能够Done掉多少故事。发现方案一的第一个Sprint的数据不足以反映团队的发布能力,而第二个Sprint的数据其实是”掺水”的相比较而言。作为“昨天的天气“(Yesterday’s weather)来估计未来是不可靠的。方案二的两个Sprint的数据都是“不掺水”的。能够更好地对未来的趋势进行估测。项目组可以对自身的能力有更清楚的认识。
- 不跟自己玩“数字游戏”,故事点只是一个工具
在Release Burnup中方案一的第二个Sprint和总的完成的故事点数都要高。项目组、管理层的会感觉沾沾自喜,哪怕这个数字是掺水的。这其实是自欺欺人,因为但是这对客户的意义不大,客户并不会关心故事点数字的高低,他们甚至不在乎你用什么工具来追踪和预测,他们更在乎的是团队是否能够按时保证质量的发布功能。使用第二种方案,会让项目组意识到最终目的并不是为了那个“更高的数字”,不要跟这个数字“做游戏”,这只是一种“局部优化”(Local Optimization)。项目组应该把关注点放到如何做到稳定的发布上。
- 鼓励“向前看,忘记过去”
敏捷开发的一个原则是“忘记过去,向前看”(Forget the past, look ahead),不必关心过去发生事情,只关注如何把剩下的工作做得更好。这其实跟我们在每天的Daily Scrum上做的一样,项目组不需要关心自己已经花费了多少,只要关心还剩多少没有完成。在做Sprint计划是也需要应用同样的原则。
